Elasticsearch - logstash 경험기 마지막
DB나 백엔드 쪽이 익숙치 않은 사람으로써, Logstash를 활용하는 것이 생각보다는 굉장히 어려웠다. 물론 지금 돌이켜보니 굉장히 단순하고 직관적으로 만들어진 것은 맞지만, 역시 경험의 간극은 메우기가 어려웠던 것 같다.
1. Logstash 구성
로그스태시는 로그 수집도구라고 볼 수가 있는데 예전에는 엘라스틱에 데이터를 밀어넣기 위해 redis 등이 많이 쓰였던 것 같은데 최근에는 아예 ELK라는 이름에서 보듯이 logstash가 대세인 듯 하다.
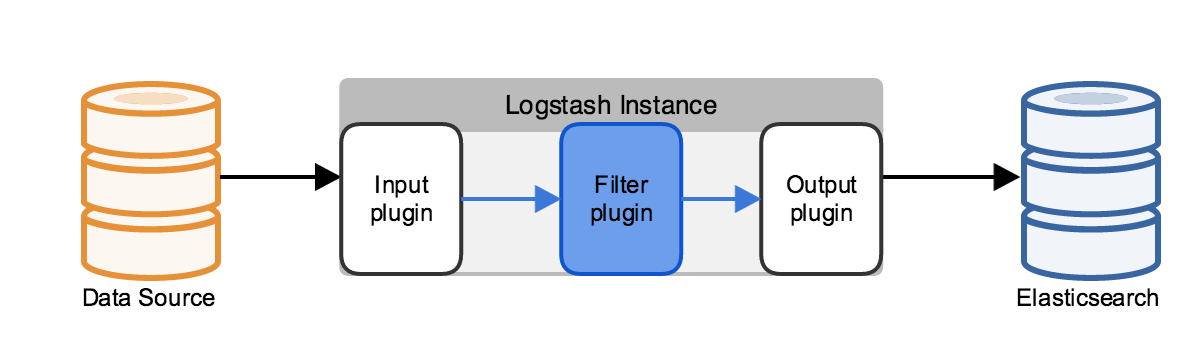
구성은 정말 심플하게 3단계의 파이프라이닝을 구성하고 있으며, plugin도 다양하게 존재한다. 낮은 버전의 로그스태시에서는 플러그인을 별도로 설치해주거나 하는 거 같은데, 내가 쓰는 5.5 버전에서는 왠만한 플러그인은 전부 built-in 되어 있는 듯.
- Input
input과 관련된 플러그인 관련 링크- 데이터를 어디서 받겠냐는 것인데 http 호출을 통한 리턴값을 받거나, TCP로 직접 로그를 받을 수도 있고, csv/json 등의 파일 뿐 아니라 twitter에서도 인풋을 받을 수 있다!!
- Filter
filter와 관련된 플러그인 관련 링크- 사실상 로그스태시의 핵심 모듈이라고 생각. 빅데이터 엔진의 가장 큰 특징은 비정형 데이터를 처리 할 수 있다는 점인데, 이 비정형 데이터라는 게 말 그대로 규약이 없다
- 다시 말해, 실제로 데이터를 활용하기 위해서는 인풋 데이터로부터 일정한 가공이 필요한데, 이러한 가공 방법을 여기서 규약한다.
- 예를 들어,
syslog를 받아 그 중에 IP만 처리하려고 한다면 정규식 등을 활용해서 다른 데이터는 없애고, 수정하고, 입력하려는 컬럼 데이터 정의하고, 특정 필드는 없애고 등등의 대부분의 작업이 된다 (심지어codeplugin으로 ruby 코드까지 돌릴 수 있다!) grok과mutate필터가 핵심인데.. 사실 아직 이 부분을 사용하기 참 어렵다.
- Output
output과 관련된 플러그인 관련 링크- output(필터링된 데이터))을 어떻게 출력하고 어디로 보낼 것이냐를 정의하면 됨
참고로 내가 만들었던 configuration은 아래와 같음.
input{
# csv file 형태로 받는다
file {
path => "...."
start_position => beginning
sincedb_path => "/dev/null"
codec => plain { charset => "UTF-8"}
}
}
filter{
# 입력받은 csv파일을 아래와 같이 쓰겠다
csv{
# csv파일의 각 header를 아래 컬럼 데이터로 집어넣고
column => [... , ... , ...]
# 이 때 각 컬럼을 구분하는 글자는 space
separator => " "
}
# Grok 은 포기하고, 아래 sample만 남겨둠
# 포기한 이유는 1) real-time에 input을 받는 게 아니고
# 2) column 개수가 너무 많아 차라리 전처리가 나음
#grok {
# match => { "message" =>
#"%{TIMESTAMP_ISO8601:timestamp}
#%{LOGLEVEL:log-level}
#\[%{DATA:class}\]:%{GREEDYDATA:message}" }
#}
mutate{
# elasticsearch로 들어가면 몇 개의 필드는 기본 생성이 됨
# 특히 message 필드는 데이터를 한방에 때려넣기 때문에 중복
remove_field => ["message", "host", "path"]
}
}
output{
# 필터링된 데이터는 엘라스틱으로 밀어넣는다
elasticsearch{index =>'aa' hosts => 'xxx:9200'}
stdout{ codec => rubydebug }
}
사실 매우 간단한 예시인데, 처음에는 저 conf. 에서 모든 걸 해줘야 깔끔한 동작이라는 강박관념에 mutate, grok을 덕지덕지 붙였는데, 복잡도만 높아지고 나중에 변경되는 데이터를 커버하기 어려워진다는 단점 이 있어서 차라리 데이터를 csv 파일로 떨구고 나서 이걸 python으로 전처리하는 것을 선택했다.
RDBMS에서 아예 데이터를 땡겨오기도 함. (데이터는 모두 내놔라 하는 듯 한..)
2. Logstash 적용간 경험상의 어려움
- 구린 환경 (이건 개인경험임..ㅋㅋ)
- 상당히 고사양이 필요한데, 내가 가진 것은 python 2.6의 CentOS…
- python 버전이 낮으면 json 파싱이나 encoding, csv 다루는데 제약이 많이 생긴다
- 끝나지 않는 프로세스
- 이게 좀 신기한데, logstash는 끝나지를 않는다. 파일에 이벤트가 새로 발생하면 언제든 땡겨간다는 철학 때문이라고 함.
- 관련링크 - stackoverflow 논의사항 포함
./logstash agent -e 'input { stdin {} } output { ANY_OUTPUT_FILTER }' < /file_path/test.log와 같이-e옵션으로 한번만 실행시키는 방법을 쓴다는데, 사실 불편함
grok,mutate활용하기- 정규식에 익숙한 사람들이면 모르겠는데, 사실 좀 익히기 어렵고..
- 특히 이게 input data가 조금이라도 형식이 바뀌면 똥망이 될 수가 있어서 유연한 설계가 필요한데 이런 걸 아직 잘 못하겠다.
- JSON parsing 간의 어려움
- 참 간단하면서 어려운 인코딩 문제와 python에서 dictionary / json 간의 호환 문제, 그리고 dilimiter 문제가 있음
- 인코딩 문제는
에라 모르겠다sys.setdefaultencoding('utf-8')로 대강 퉁쳐버렸고, dilimiter는 ‘$’로 처리해버림
3. 느낀 점
냉정하게 얘기해서, 위의 테스트는 elasticsearch를 아주 잘 활용할 수 있는 형태의 데이터는 아니다. elasticsearch를 쓰려고 하려면 우선 input/output이 빈번히 발생하고 near real-time 을 표방하는 것에 맞게 즉각적인 답변을 원하며, 마지막으로 다양한 소스로부터의 데이터를 받아들여야 하는 환경일 때 적합할 것으로 생각한다. 따라서, 위의 시스템 정보나 이력들(json 파일로 약 8G)은 사실 굳이 elastic search가 아니라 그냥 mysql 같은 RDBMS에 넣어도 충분할 것으로 생각한다.
하지만, DB를 설정하고 활용하는 장벽이 사실 크다. 실제로 어느 정도 규모 이상의 회사에서는 망 구조를 DB존을 별도로 만들고 쿼리를 만들거나 날릴 수 있는 권한은 일부 관리자에게만 제공 한다.
그 얘기는, 의미가 있는 대규모의 데이터들(이런이런 조건을 가지는 IT장비들의 전체 현황과 보안 점수를 본다거나, 방화벽 룰을 본다는 등)을 볼 때 꽤 장벽이 상당히 큰 것이 사실이다. 통계 페이지를 별도로 만들어서 미리미리 준비해둘 수도 있지만, 이것은 굉장히 데이터를 정적으로 활용하는 방법일 수 밖에 없다.
아이디어가 있고, 어떤 의미의 데이터를 좀 보고싶다 할 때 간편하게 바로 볼 수 있다는 점이 큰 매력이며 결국 data를 활용하기 위해서는 그게 늘 곁에, 편리하게 살펴볼 수 있어야 하지 않을까 한다는 점에서 좋은 툴인 듯 하다.